24.9% Conversion Rate From ChatGPT: Live Data From a Controlled Experiment
Can a brand-new domain with no backlinks earn AI citation — and convert?
David Valencia · February 25, 2026
Summary
WhatsMyArtWorth.com launched on December 10, 2025 as a controlled experiment. The question was simple: could a brand-new domain with no backlinks, no advertising budget, and no existing audience earn citation from AI systems — and could those citations convert into real leads?
The answer was yes. ChatGPT traffic converted at 24.9% — calculated from 122 leads against 490 total February sessions. The industry benchmark for landing page conversion is 2-4%. That is not a marginal difference. It is a signal that AI-referred users arrive with intent that organic search traffic rarely matches.
The first AI-referred lead arrived 33 days after launch. By February, the site was averaging 4 leads per day with zero acquisition cost. Google delivered 22 clicks over the entire three-month measurement period. ChatGPT outperformed every organic search channel combined — Bing, Google, DuckDuckGo, and Yahoo — on a domain that did not exist 60 days prior. These are not comparable systems operating on comparable signals.
Supporting that conversion rate are two findings that have not been documented elsewhere. First, removing over-optimized content from the homepage — content that restated what AI could already infer — produced an immediate improvement in citation behavior. Less content, aimed more precisely at what the site uniquely provides, outperformed more content aimed at covering more ground. Second, one user who had submitted an appraisal request followed up via email requesting expedited review, using a contact address that does not appear anywhere on the page. That address exists in exactly one place: the Organization schema in the site's JSON-LD. The inference is that they asked ChatGPT for contact information and ChatGPT returned it directly from the structured data. If accurate, JSON-LD is not a technical SEO checkbox. It is a direct communication channel between a site and an AI's users.
1. The Problem With Asking AI How AI Works
When the SEO industry asked AI systems how they evaluate and cite sources, AI gave a clean answer: prioritize authority, institutional backing, government sources, verifiable data, and domain credibility. The industry optimized for those signals. That optimization produced more content articulating those same signals, which AI then absorbed, which it repeated the next time someone asked. The loop closed.
This is the echo chamber problem. It is not unique to AI. SEO has operated this way for two decades. Keyword density was debunked and practitioners optimized for it for years. PageRank was misunderstood and entire industries built around the misunderstanding. The pattern is consistent: a mythology forms, spreads, gets absorbed into the conventional wisdom, and the myth becomes louder than the evidence against it. The debunk rarely travels as far as the original claim.
AI did not invent this problem. It inherited it. Every piece of content the SEO industry produced explaining how to rank — how to build authority, how to earn backlinks, how to signal credibility — became training data. When practitioners ask AI how to earn citation, AI returns the mythology it was trained on. That does not make the mythology true. It makes it persistent.
This experiment was designed to test whether the stated framework holds up against observed behavior. WhatsMyArtWorth.com has none of the signals AI says it values: no domain history, no backlinks, no institutional affiliation, no government endorsement. It launched as a new domain and within 60 days ChatGPT was converting at 24.9% — outperforming every organic search channel combined. The conventional wisdom was not just incomplete. It was describing a different category of site entirely — content sites built for search engines — and the industry applied it wholesale to AI citation without questioning whether the same rules applied.
They do not.
2. Experiment Context
The site exists to answer one question that AI cannot: what is this specific piece of artwork actually worth? AI systems can explain how art valuation works in general. They cannot appraise a painting sitting on someone's kitchen table. That gap — between general knowledge and specific human action — is what the experiment was designed to occupy.
The art market compounds this gap with a specific intent problem. The space is not short of content — established players cover inherited art, estate sales, auction placement, and valuation extensively. But that content assumes the user already knows their art has value and needs guidance on what to do next: sell it, insure it, donate it, consign it. The underserved intent sits one step earlier. The person who inherited a painting and does not know whether it is worth $50 or $50,000 — and needs to find out before they can decide anything — has almost no content built specifically for them. Every competitor answers what to do with inherited art. This site answers whether it matters in the first place.
The hypothesis was that a site occupying a genuine completion gap, aimed at a pre-decision intent that established competitors had not targeted, built with clean static HTML and structured content AI could parse and cite, would earn citation faster than traditional SEO authority signals would predict.
The technical stack is intentionally minimal: pure static HTML with a single CSS file and minimal vanilla JavaScript. The domain is connected on Cloudflare. The site runs on a Digital Ocean Apps plan at $3 per month.
3. Timeline
December 7, 2025 — Domain registered.
December 10, 2025 — Site launched. Static HTML homepage with full schema, FAQ, and appraisal form via Typeform embedding.
December–January — 180 total sessions over the period. Traffic is dominated by direct (141 sessions, 78.33%). Six sessions from ChatGPT appear in the data. Google Analytics attribution is known to undercount AI traffic during this period; the more reliable signal is Typeform referrer data.
January 12, 2026 — First confirmed lead from AI. The signal was unambiguous: a Typeform submission referrer URL showing ?utm_source=chatgpt.com. ChatGPT had cited the site and a user had followed the citation, navigated to the form, and submitted an appraisal request.
February 2, 2026 — Site relaunched with a structural change to the homepage: content that could be inferred from site context was removed. The original homepage was over-optimized — it restated things AI could already infer, adding noise rather than signal. The relaunch stripped that content down to what the site uniquely provides. AI crawl behavior shifted after this change. Google did not respond in any meaningful way.
February 2026 — 490 sessions over 28 days. ChatGPT becomes the second-largest traffic source. The form is updated mid-month to support three reference image uploads instead of one, improving the submission experience for users with multiple artwork photos.
February 28, 2026 — Measurement period closes. 122 total leads for the month. Referrer data confirms AI as a conversion source throughout.
4. The Data
4a. AI Crawl Behavior
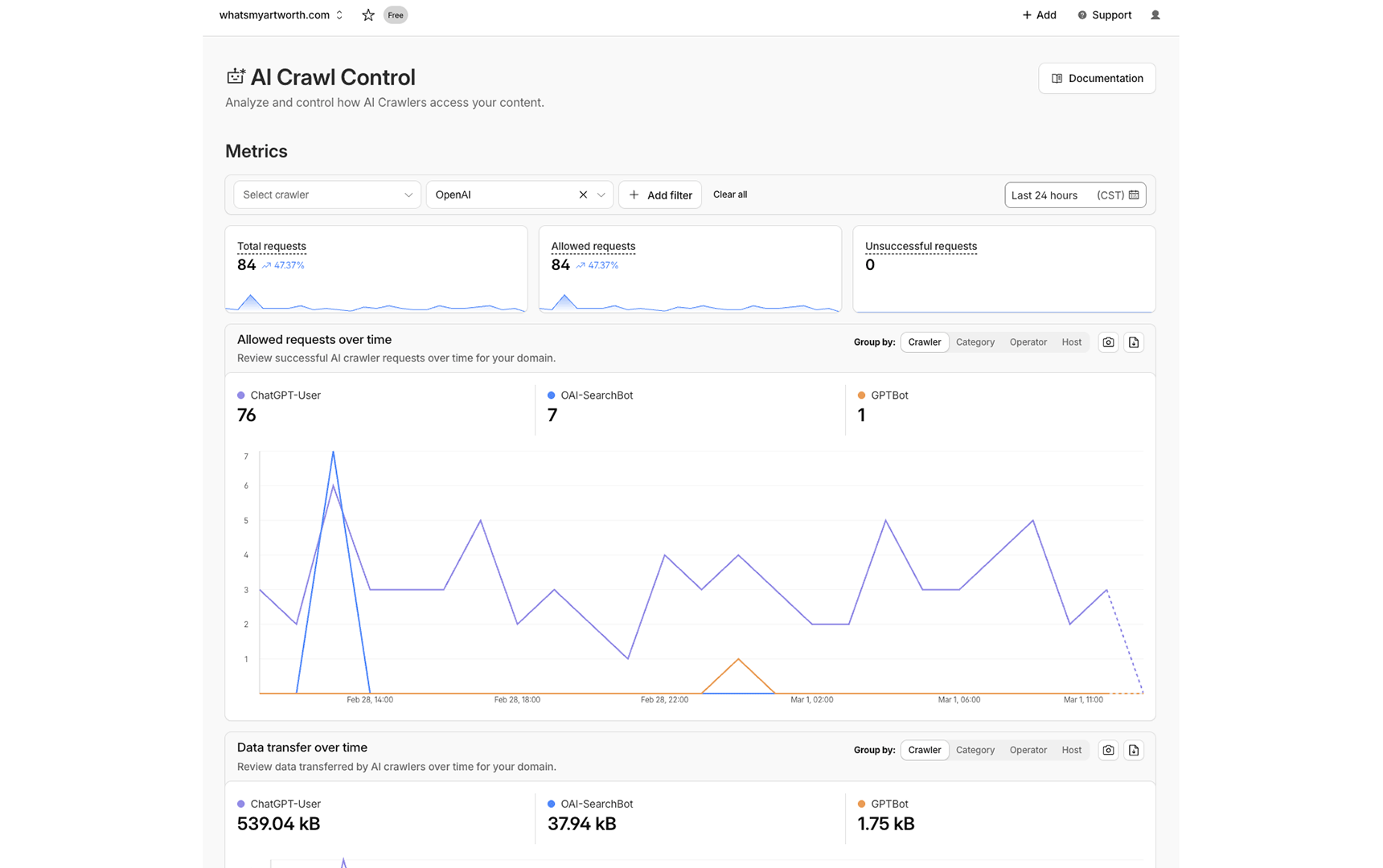
Cloudflare's AI Crawl Control dashboard provides infrastructure-level visibility into how AI systems interact with the site. Filtered to OpenAI alone, the last 24-hour snapshot shows 84 total requests, all allowed, none unsuccessful. ChatGPT-User accounts for 76 of those requests, OAI-SearchBot for 7, and GPTBot for 1. The three crawler types represent three distinct functions: ChatGPT-User is real-time retrieval triggered by active user queries, OAI-SearchBot is index building, and GPTBot is training data collection. All three are active simultaneously.
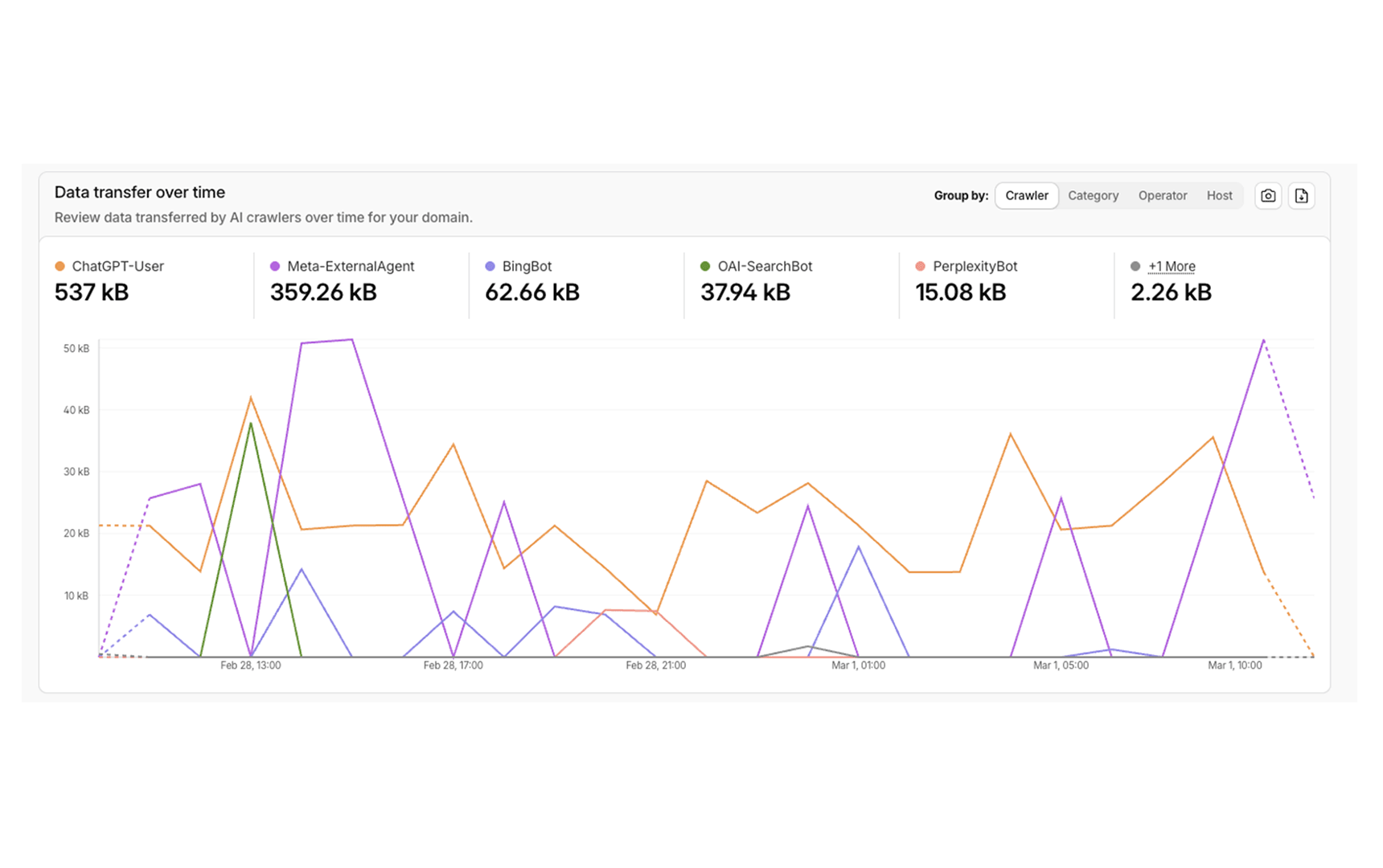
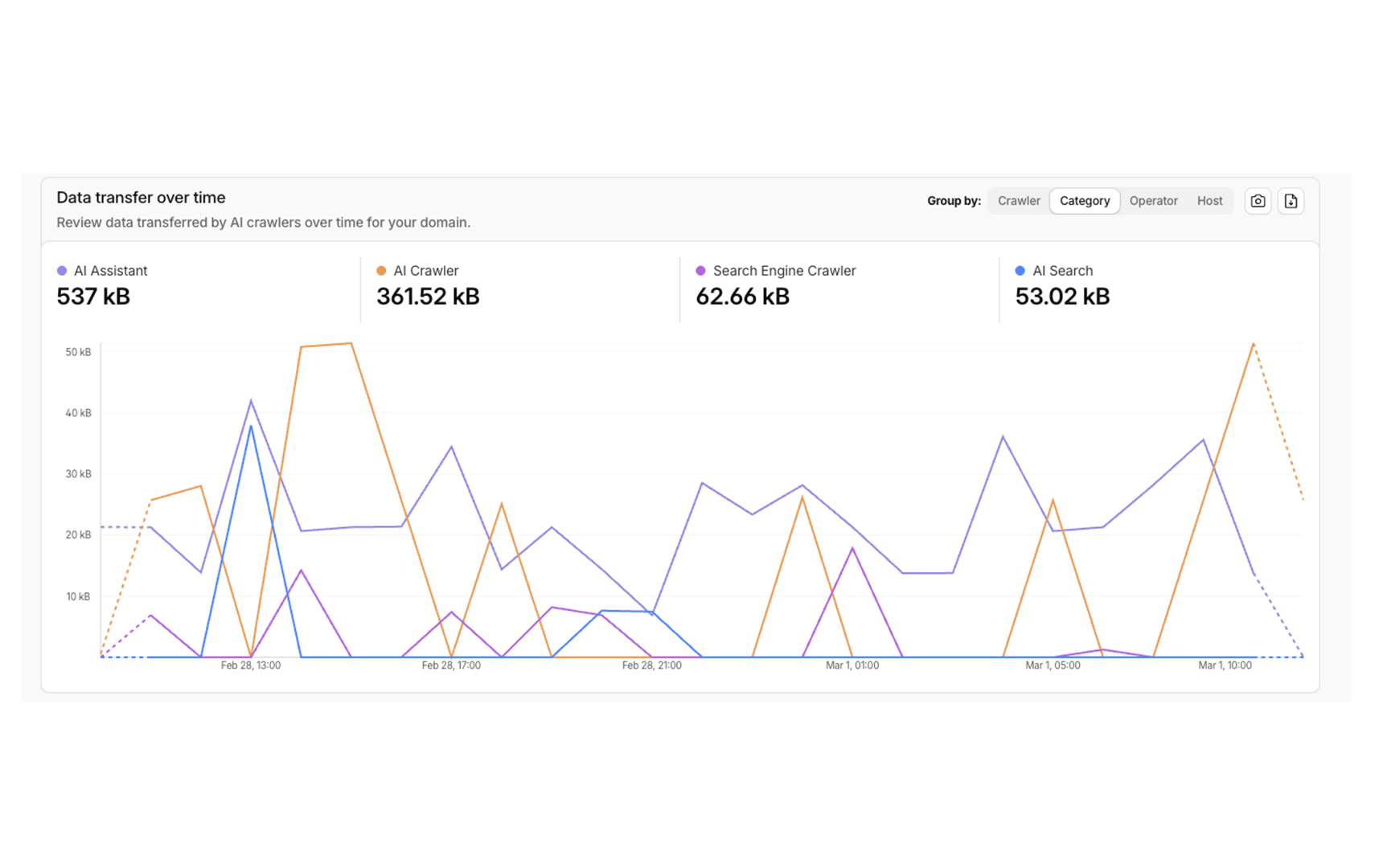
The category view tells the clearest story. AI Assistant traffic (537kB) represents users actively querying an AI product that fetches the site in real time. AI Crawler (361.52kB) is autonomous indexing. Search Engine Crawler (62.66kB) is traditional Bing bot activity. AI Search (53.02kB) is crawling tied to AI-powered search interfaces. Together, AI-category traffic accounts for the overwhelming majority of non-human requests. Traditional search crawlers are a minority of the machine traffic this site receives.
4b. Why Page Weight Matters for AI Citation
Google preached page speed for over a decade. The stated reason was user experience. The underlying mechanic was crawl budget — Google has finite resources and rewards sites that are cheap to process. AI systems have the same constraint, but the cost is explicit, measurable, and paid in real dollars on every retrieval request. That cost is tokens.
To measure this directly, the full HTML source of WhatsMyArtWorth.com and the top organic search competitor in the same niche were each pasted into the OpenAI tokenizer. The results:
WhatsMyArtWorth.com: 5,882 tokens, 23,793 characters.
Top organic competitor: 112,437 tokens, 363,286 characters.
That is a 19.1x token difference for two pages answering the same query. Every time an AI system retrieves and processes a page to generate a response, it pays a token cost. A page that costs 19x more to process is 19x more expensive to cite. Engineers at every major AI platform are incentivized to optimize retrieval costs — it is the nature of the problem. When two pages answer the same question, the one that delivers the answer at a fraction of the token cost has a structural advantage that has nothing to do with authority, backlinks, or domain age.
The transfer size data reinforces the same finding from a different angle. WhatsMyArtWorth.com HTML document: 6.5KB transferred. Top organic competitor: 1.0MB transferred. That is a 153x difference in transfer size for two sites competing for the same user query.
4c. Traffic Sources
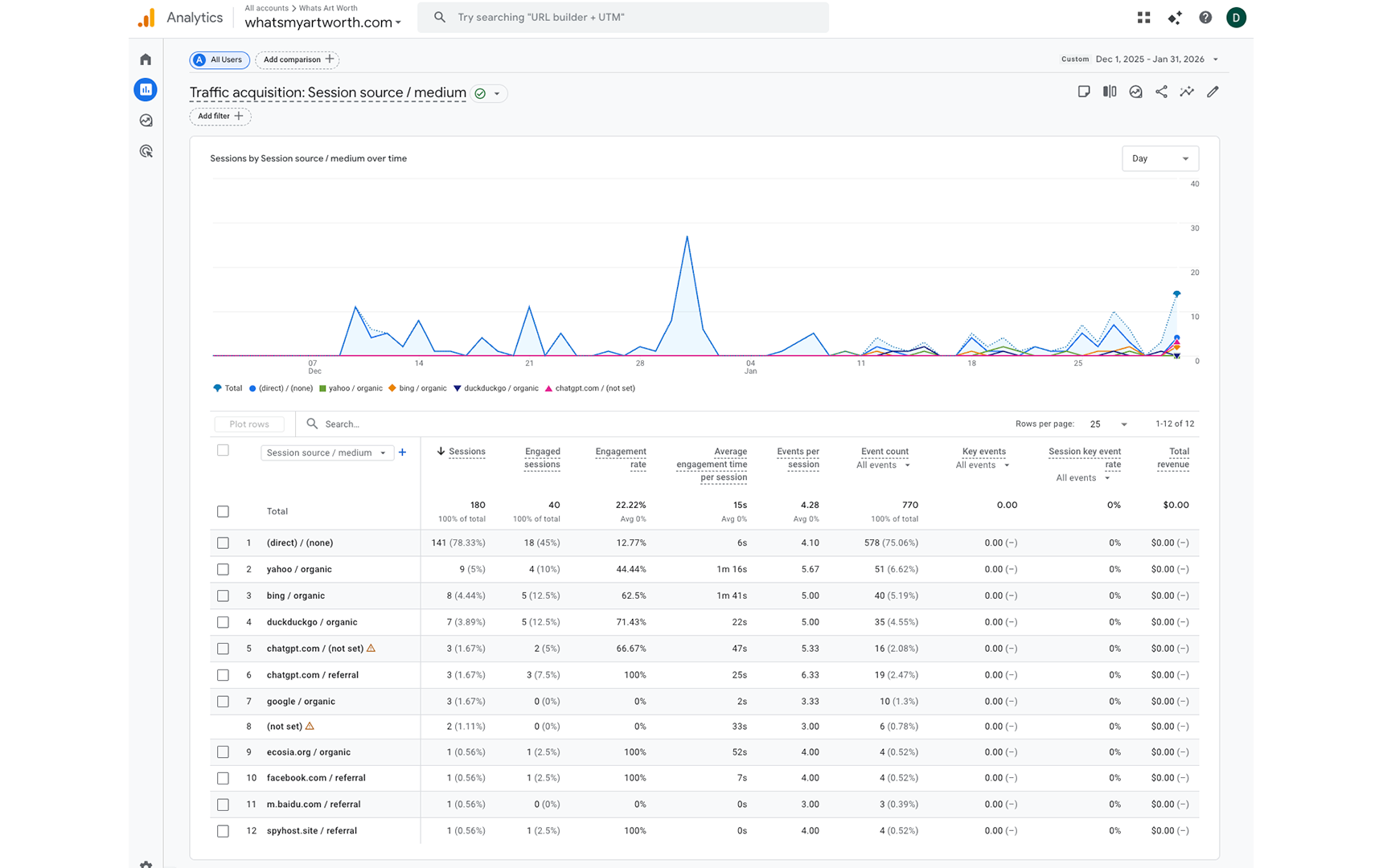
The December–January period establishes the baseline. Traffic is low and heavily weighted toward direct — consistent with a new site with no promotional activity. ChatGPT registers 6 sessions across two attribution buckets. Typeform referrer data is the more reliable source for AI conversion tracking during this period.
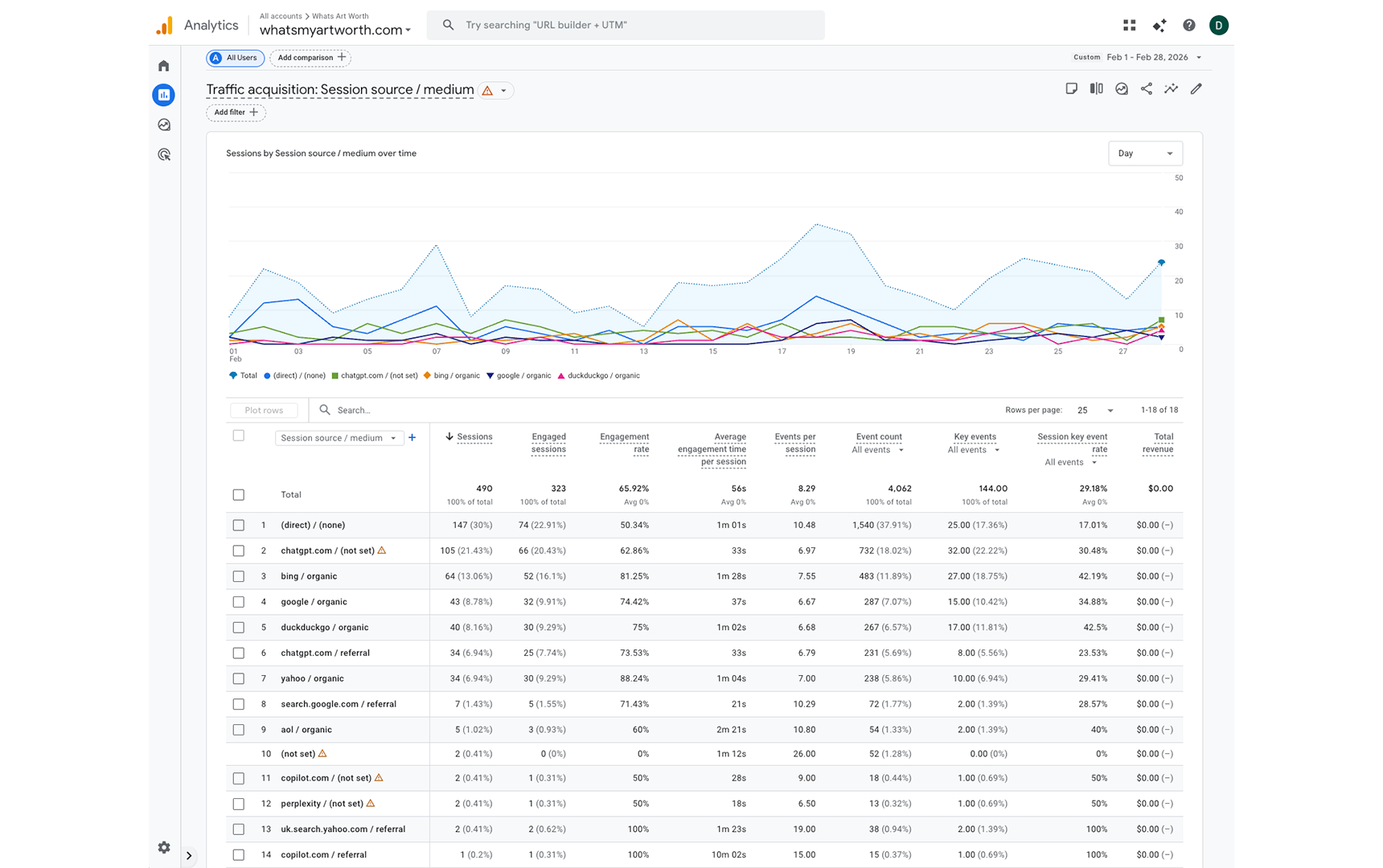
February is where the experiment produces its core findings. Total sessions more than doubled from the prior two-month combined total to 490 in a single month. ChatGPT accounts for 139 sessions (28.37%), trailing only direct traffic at 147 sessions (30%). Copilot appears across two attribution rows totaling 3 sessions. Perplexity registers 2 sessions. Combined, AI-attributed sessions account for approximately 144 of 490 total February sessions — 29.4%.
Two organic search sources stand out for engagement quality. Bing organic delivered 64 sessions with an 81.25% engagement rate and an average engagement time of 1 minute 28 seconds. Yahoo organic's 34 sessions show an 88.24% engagement rate. Both outperform ChatGPT sessions on engagement metrics, which is consistent with search users arriving with higher task-specific intent. The ChatGPT sessions convert — they submit the form — but they engage differently than search users.
4d. Search Performance
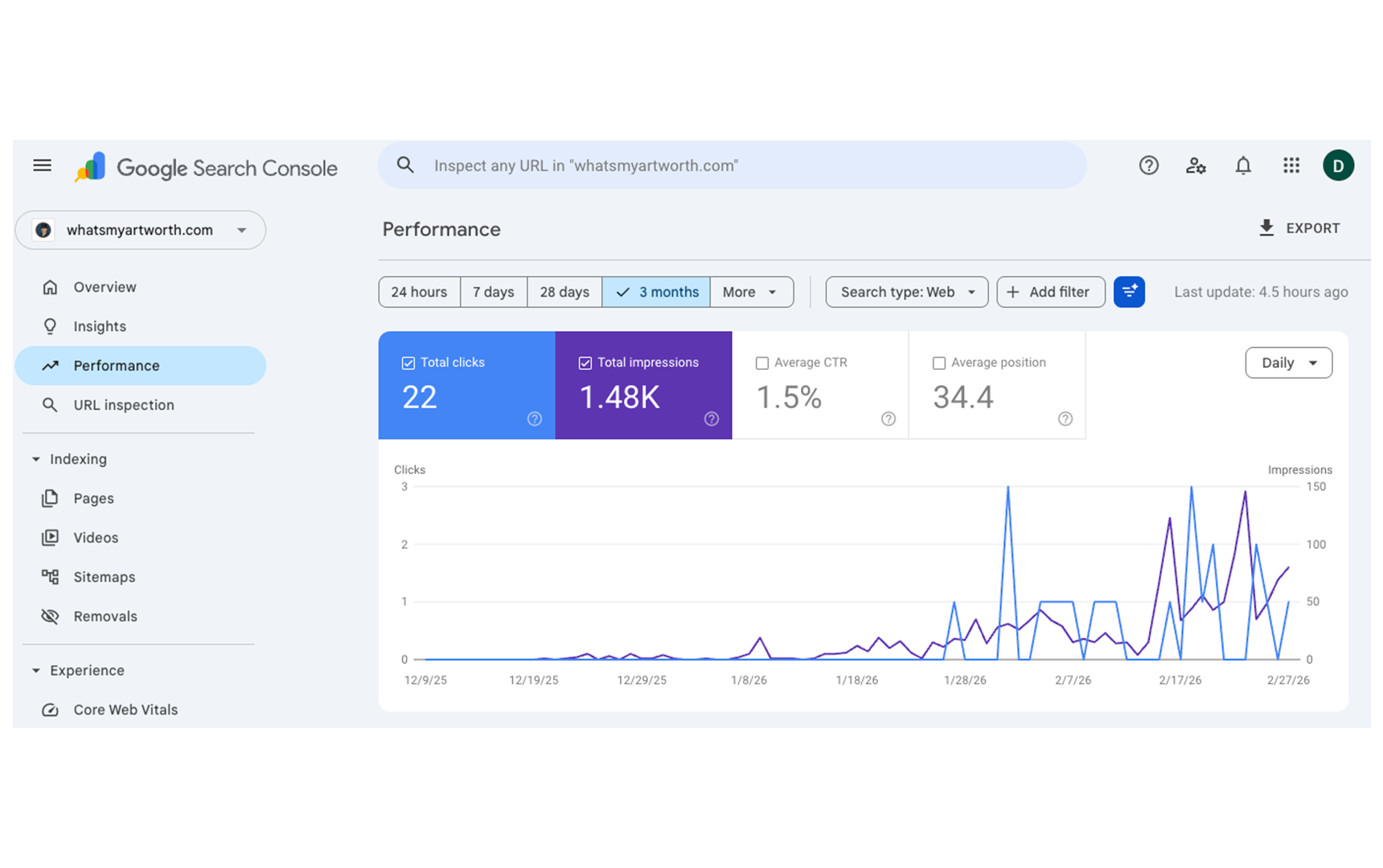
Google delivered 22 clicks over three months. Against 490 February sessions, that contribution is effectively marginal. The February 2 structural change that shifted AI crawl behavior and citation produced no corresponding response from Google. This is not a secondary finding — it is central to what the experiment demonstrates. The same content and architecture changes that AI systems responded to immediately, Google largely ignored.
The two systems are not measuring the same signals. Practitioners who treat Google ranking as a proxy for AI citability are optimizing for a different problem.
4e. Conversion and Lead Data
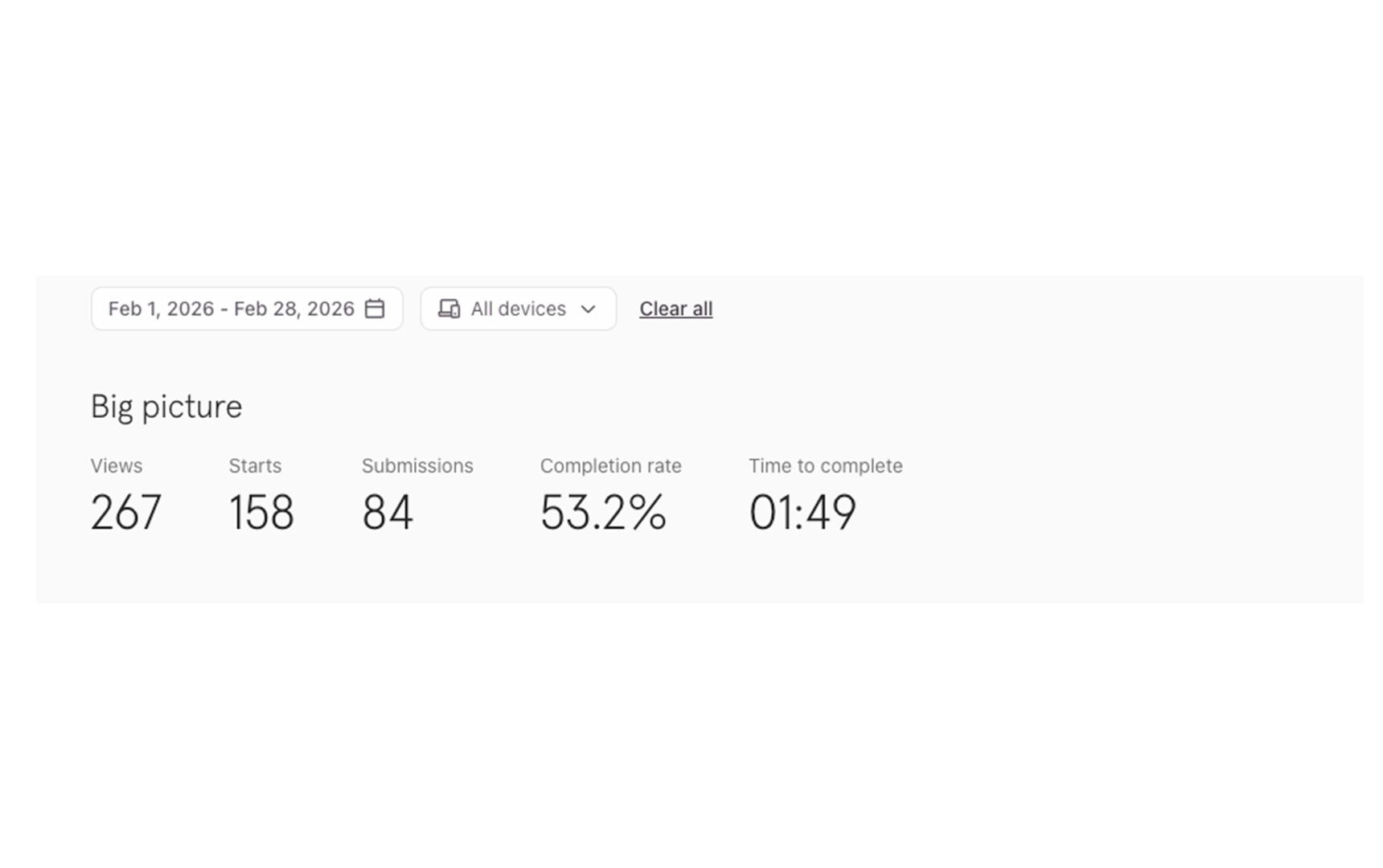
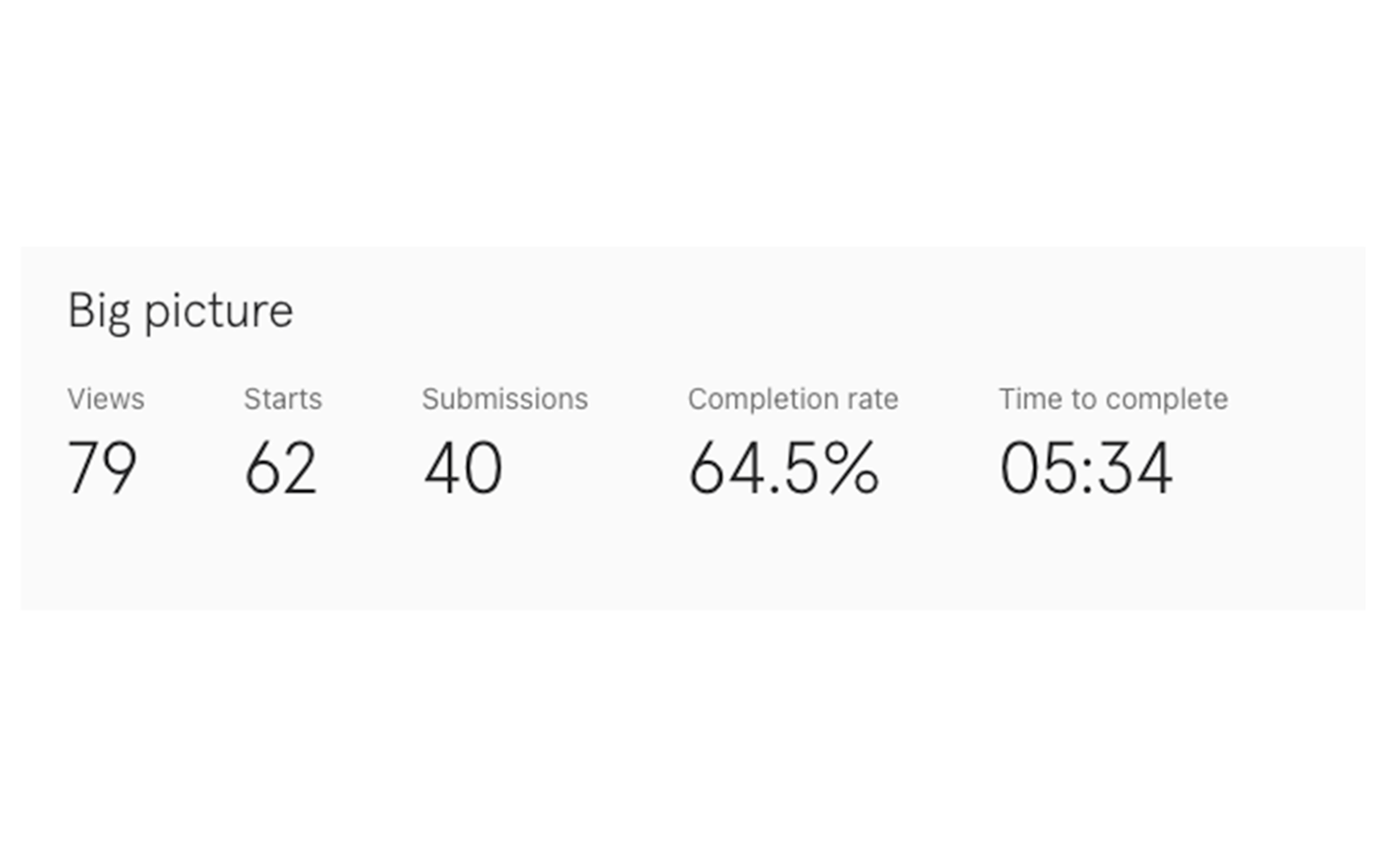
Two Typeform instances ran during February because the form was updated mid-month to support three reference image uploads instead of the original single upload. Both forms were active concurrently during the transition period. Together they represent the full lead picture for the measurement period, with 122 total leads across 490 February sessions — a 24.9% conversion rate.
The industry benchmark for landing page conversion is 2-4%. A 24.9% rate against a traffic source — ChatGPT — that the SEO industry treats as secondary to Google represents a meaningful divergence from the conventional framework. The site Google has not prioritized is converting at 6-10x the standard benchmark from the traffic source Google does not control.
The completion rate difference between the two forms is also notable: 53.2% on the original versus 64.5% on the updated form. Users submitting three images spend significantly more time (5:34 versus 1:49) but complete at a higher rate, suggesting the additional upload requirement filters for more motivated leads rather than deterring them.
4f. AI Citation Proof
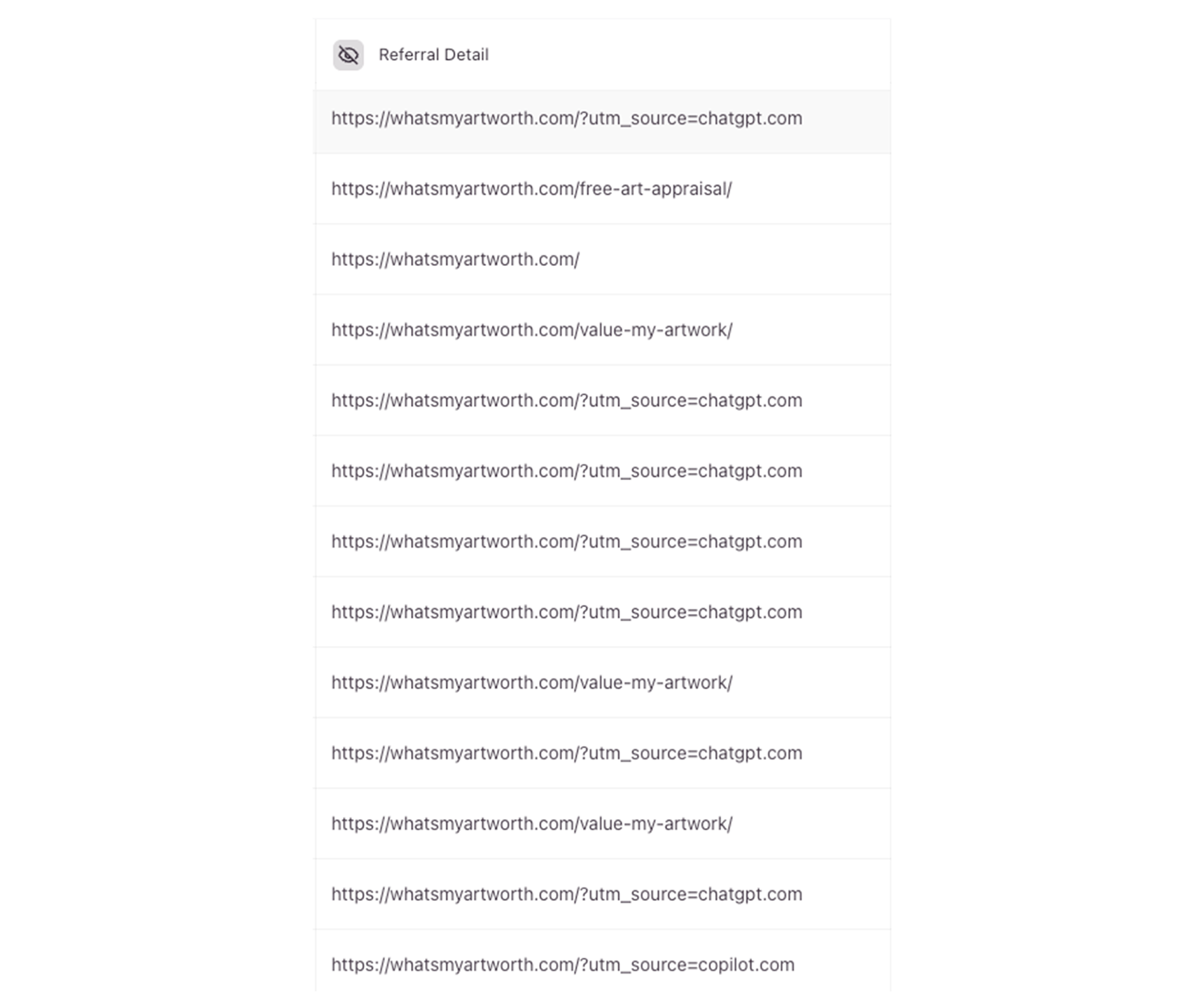
This is the most direct evidence in the dataset. The Typeform referrer detail shows the actual URLs users arrived from before completing an appraisal request. Entries marked ?utm_source=chatgpt.com appear multiple times. One entry shows ?utm_source=copilot.com. These are not traffic estimates or attribution models — they are the literal referrer strings captured at the moment of form submission.
AI systems cited WhatsMyArtWorth.com in response to user queries about artwork valuation, users followed those citations, navigated to the appraisal form, and submitted requests. The citation chain completed.
5. Key Findings
ChatGPT traffic converted at 24.9% against an industry benchmark of 2-4%. 122 leads from 490 February sessions. That is 6-10x the standard benchmark for landing page conversion. AI-referred users arrive with specific intent — they have already asked a question, received a recommendation, and followed it. That behavioral profile produces conversion rates organic search traffic rarely achieves.
The first AI-referred lead arrived 33 days after launch. The domain did not exist on December 10, 2025. On January 12, 2026, a Typeform submission referrer URL showed ?utm_source=chatgpt.com. No backlinks, no advertising, no promotion. ChatGPT cited the site and a user followed the citation and submitted a request within 33 days of launch.
By February the site was averaging 4 leads per day with zero acquisition cost. 122 leads over 28 days. The cost of acquiring each lead is the $3 per month Digital Ocean hosting plan divided across 122 submissions. There is no ad spend, no SEO agency, no link building campaign.
ChatGPT outperformed every organic search channel combined. Bing organic delivered 64 sessions. Google organic delivered 42. DuckDuckGo delivered 40. Yahoo delivered 34. ChatGPT delivered 105. On a domain Google has not prioritized — 22 clicks over three months — AI citation produced more referred traffic than every traditional search engine combined.
Citation converted. The referrer URL data proves it. The Typeform referrer detail shows the actual URLs users arrived from before completing an appraisal request. Entries marked ?utm_source=chatgpt.com appear multiple times. One entry shows ?utm_source=copilot.com. These are not traffic estimates or attribution models — they are the literal referrer strings captured at the moment of form submission. The citation chain ran all the way through to a lead.
Page weight is a structural advantage for AI citation — measured in tokens and transfer size. WhatsMyArtWorth.com: 5,882 tokens. Top competitor: 112,437 tokens. That is a 19.1x token difference for two pages answering the same query. Transfer size: 6.5KB versus 1.0MB — a 153x difference. Token costs are a real operating expense for every AI platform. A page that delivers the same answer at a fraction of the token cost has a structural advantage that has nothing to do with authority, backlinks, or domain age.
Removing over-optimized content improved citation behavior. The February 2 relaunch stripped the homepage of content that restated what AI could already infer from context. AI crawl behavior shifted after the change. Google did not respond. The implication is that content AI can generate on its own adds noise rather than signal. The site does not need to explain what AI already knows. It needs to provide what AI cannot generate.
JSON-LD schema appears to be a direct communication channel to AI users. One user who had submitted an appraisal request followed up via email requesting expedited review, using a contact address that does not appear anywhere on the page — only in the Organization schema in the site's JSON-LD. The inference is that they asked ChatGPT for contact information and ChatGPT returned it directly from the structured data. This is stated as an inference, not a proven mechanism. But if it holds, what practitioners put in schema may be what AI users receive without ever visiting the page.
The completion gap drove citation, not authority signals. AI can explain art valuation methodology. It cannot produce a valuation document for a specific object. That gap is why AI cited this site rather than generating an answer itself. The liability attached to the question — someone could make a financial decision based on a wrong answer — increases citation probability. AI cites to shift responsibility for high-stakes answers to a human source.
The gap was not absence of competition — it was a question nobody was answering. The art market has substantial content covering inherited artwork, estate valuation, and selling decisions. All of it assumes the user already knows their art has value. This site targets the prior question: is it worth anything at all? Every established competitor answers what to do with inherited art. This site answers whether it matters in the first place. That one step earlier is where the citation gap lived.
62.1% of February traffic arrived on mobile. Safari was the dominant browser, followed by Chrome, then Edge — consistent with iOS users arriving via the ChatGPT mobile app or Safari on iPhone.
6. What Surprised Us
The speed surprised us. The hypothesis was that AI citation was achievable on a new domain without traditional authority signals. The hypothesis did not predict that ChatGPT would convert at 24.9% within 60 days, or that it would outperform every organic search channel combined on a domain Google had largely ignored.
The schema email finding surprised us more than any traffic number. A user who had already submitted an appraisal request followed up via email requesting expedited review — using a contact address that does not appear anywhere on the page. The only place that address exists is in the Organization schema in the JSON-LD. The inference is that after submitting the form, they asked ChatGPT for contact information and ChatGPT returned the schema address directly. If that inference holds, schema is not just infrastructure. It is the message itself. What practitioners choose to put in Organization schema, FAQPage entries, and service descriptions may be what AI reads and returns when a user asks about a business. That changes how schema should be thought about and built.
The February 2 finding also produced a counterintuitive interpretation. The assumption going in was that more content means more signal for AI to parse. The data showed the opposite: removing content that could be inferred from context improved citation behavior. Over-optimization — adding content to cover more ground — appears to dilute the signal rather than strengthen it. The site did not need to explain what AI already knows. It needed to provide what AI cannot generate on its own.
7. Limitations
This is a single experiment on a single domain in a specific niche. The art appraisal niche has characteristics that may not generalize: high liability, a clear completion gap, and a pre-decision intent that established competitors had not specifically targeted. Sites in lower-liability niches, or niches where AI can provide more complete answers, may not replicate these results.
GA4 attribution for AI traffic is imperfect and known to undercount. The 29% figure is a floor, not a ceiling. Typeform referrer data is more reliable for conversion tracking but captures only the users who made it to the form.
The Cloudflare crawl data represents a 24-hour snapshot, not a monthly aggregate. The crawl activity shown is consistent with what was observed throughout February, but the report presents a point-in-time view.
The experiment cannot isolate which specific elements drove citation. The February 2 relaunch changed content scope simultaneously across the page. Identifying which specific content removal caused the inflection would require controlled testing that was not part of this experiment's design.
The schema email finding is an inference. The user confirmed they had submitted a form and followed up requesting expedited review, using an email address that does not appear anywhere on the page — only in JSON-LD schema. How they obtained that address was not confirmed. The inference that they asked ChatGPT and ChatGPT returned the schema data is plausible but unverified. It is reported here because it warrants attention, not because it is proven.
The form submission referrer data confirms ChatGPT and Copilot as citation sources but does not show which specific queries triggered those citations, what the AI said about the site, or where in an AI response the site appeared.
The token cost measurement uses the OpenAI tokenizer applied to raw HTML source. This is a proxy — it measures tokenization under one model's vocabulary, not the exact cost any specific AI system pays per retrieval request. Different models tokenize differently. The finding directionally holds across any tokenizer but the specific 19.1x ratio should be treated as an order-of-magnitude comparison, not a precise cost calculation.
8. Implications
The SEO industry built its framework by asking AI how it evaluates sources. AI told the industry what it had absorbed from the SEO content it was trained on. That is not a reliable methodology for understanding AI behavior — it is a closed loop that confirms whatever the training data already said. The observed behavior in this experiment diverges from the stated framework in every meaningful dimension: domain authority did not predict citation, Google ranking did not correlate with AI citation, and the highest-converting traffic source is one traditional SEO cannot optimize for.
The practical implications follow from the data, not from what AI says about itself.
JSON-LD schema deserves to be treated as more than a technical checkbox. The schema email finding — if it holds across other experiments — means structured data is a communication layer between a site and AI users who may never visit the page. The Organization schema, FAQPage entries, and service descriptions may be what AI reads and returns directly. What goes in that schema matters. This finding is consistent with patterns observed across multiple client sites, where the presence or absence of JSON-LD schema correlates with measurable differences in AI-referred traffic. A controlled study isolating this variable is in progress.
Removing content that can be inferred from context appears to improve citation signal. The February 2 relaunch stripped the homepage of content AI could already generate. Crawl behavior improved. Over-optimization — covering more ground with more words — does not appear to add citation value. It adds noise.
Completion gaps earn citation more reliably than content quality. AI cites when it cannot complete the action itself. A site that does what AI cannot do — produce a specific output for a specific person — is more citable than a site that explains what AI already knows how to explain. High-liability niches accelerate this effect. When being wrong has financial or legal consequences, AI cites rather than answers.
Intent gap is the first variable to evaluate before building. The question is not whether a niche has competition — most viable niches do. The question is whether the competition is answering the same question your user is actually asking. The art appraisal space is well covered for users who already know they have something valuable. It was not covered for users who do not know yet. That one step earlier — the pre-decision question — is where a new domain with no authority can earn citation faster than an established domain answering a different question in the same niche.
Build lean. Token cost is the AI-era equivalent of page speed — except the cost function is explicit and paid in real dollars on every retrieval request. A page that delivers a complete, specific answer at 5,882 tokens has a structural advantage over a page that delivers the same answer at 112,437 tokens. That advantage is not editorial — it is economic. It is already embedded in how AI systems are built and optimized. Every element on a page that AI can infer from context is a token cost with no citation return.
Typeform referrer URLs are currently the most direct method for confirming AI citation conversion. GA4 captures AI traffic imperfectly. If you are building for AI citation and want to verify whether it is working through to conversion, the form submission referrer is where to look.
Cloudflare AI Crawl Control provides crawler-level visibility that GA4 cannot. Which bots are active, how much data they are reading, and whether requests are succeeding — this visibility is not available in standard analytics tooling and is worth setting up on any site being built for AI citation.
Mobile-first is not optional. 62.1% of February traffic arrived on mobile. Build and test there first.
9. What's Next
Visit the Live AI Data Feed to see how AI is interacting with the sites behind this research. It shows a rolling 24-hour view of crawler activity across the properties we operate, including which AI crawlers are hitting each site, how often they are requesting pages, and how much data they are pulling.
Some of those sites are already named. WhatsMyArtWorth.com is there with its live AI crawl activity visible, so you can see how the same type of architecture discussed in this experiment is being interacted with by AI systems in production.
Other properties remain anonymous because they are ongoing AI experiments still in progress. They are controlled builds we are using to test different variables, niches, and content structures before publishing full write-ups.
As each experiment concludes, the sites will be named, linked, and documented with the same measurement approach used in this article. That includes negative results. The live data page is where to watch the crawl behavior now; the research articles are where the final findings will be published.

David Valencia is the founder of Minnesota AI — a field lab for AI discoverability engineering. He runs controlled experiments on how AI systems find, parse, cite, and route users to websites, and publishes the data openly.